Introduction
Industrial Data Collector is an integration tool to:
Collect data from OPC UA Servers;
Store that data in the Local Storage and immediately Forward into the destination persistent storage. Currently it can forward data to:
Apache Kafka, including managed instances by Confluent and Redpanda
InfluxDB (versions 1.x and 2.x),
Microsoft SQL Server
MQTT Brokers, such as HiveMQ, EMQX, Mosquito, and AWS, Azure, Google cloud platforms’ MQTT endpoints,
MySQL database,
TimescaleDB (PostgreSQL database optimized to store time-series data),
PostgreSQL,
Snowflake,
SQLite
This enables next steps to process collected data, such as:
Visualize it, using Grafana and its
SimpleJsonorInfinitydata source plugins. In this case Industrial Data Collector can feed historical or real-time data via its REST endpoint. It can fetch data directly from OPC UA Servers, or from the persistent storage where data was forwarded to before.Analyze stored in the persistent storage historical data. For example, when data is stored in SQL database, you can analyze data using standard SQL queries.
Context diagram of the Industrial Data Collector follows below.
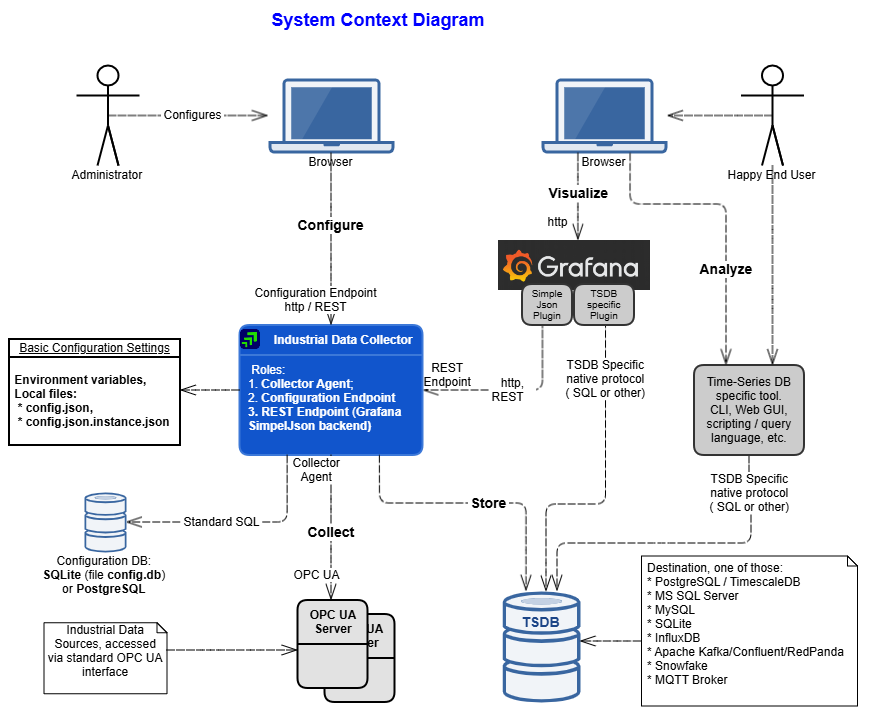
For more information on supported features, please refer the section Features.